STA551 E-Pack: Foundations of Data Science
West Chester University
Topic 1 Introduction
This E-coursepack is a self-contained homegrown eBook that contains all topics covered in current STA551 at WCU.
Data science is a young discipline, but it is becoming more and more significant in both academia and industry. It is not a sub-field of any existing well-developed disciplines. Its foundation is built on theories and techniques and drawn from applied statistics and mathematics, machine learning, database and information technology, communication and related domain fields. Proficiency in programming with languages such as Python, SQL, R, etc. is essential to perform any data science tasks.
Data science has an interdisciplinary nature, collectively uses existing tool from different fields, and creates new knowledge and tools to overcome new challenges . There are debates on the definition of data science and validity of naming the emerging interdisciplinary field as data science.
1.1 The Origin of Data Science
The idea of expanding the horizon of classical statistics can be traced back to John Tukey’s paper The future of data analysis (1962), Although not mentioning the term data science, Tukey urged statisticians to reduce their focus on statistical theory and engage with the entire data-analysis process: procedures for analyzing data, techniques for interpreting the results of such procedures, ways of planning the gathering of data to make its analysis easier, more precise or more accurate, and all the machinery and results of (mathematical) statistics which apply to analyzing data: These are foundational components of present new field of data science.
John Tukey was a chemist, topologist, educator, consultant, information scientist, researcher, statistician, data analyst, and corporate executive. At the end of World War II, he began a joint industrial and academic career at Bell Telephone Laboratories and at Princeton University (1946-1985) before he retired.
30 years after the Tukey’s prophesied “new science”, John Chambers, Tukey’s colleague at Bell and a co-inventor of the S language (R and S-Plus are both implementations of S), published an article Greater or lesser statistics: a choice for future research in which he thought statistics research was on crossroad and need to rethink whether the field needs to be expanded. Chambers came up with two contrast views of statistics: Lesser Statistics (the classical statistics built based on the probability theory) and Greater Statistics (the data-driven research which is the part of Tukey’s unnamed New Science). He thinks the if statisticians remain aloof, others will act. Statistics will lose; in addition, I believe science and society will lose also since statistician’s mental attitude at its best provides qualities likely to be missing otherwise.
The term data science was first used in scientific community in 1968 by Peter Naur (an astronomer and computer scientist/professor), in an unpublished text in which he defined data science to be ‘The science of dealing with data, once they have been established, while the relation of the data to what they represent is delegated to other fields and sciences.’.Apparently, Naur’s “data science” was not meant a discipline.
Jeff Wu, an established statistics professor, first used the term data science in a lecture given in 1985 as an alternative of statistics. Later, in an inaugural lecture at the University Michigan in 1997, he called for statistics to be renamed data science and statisticians to be renamed data scientists.
William Cleveland, a statistics professor (at Purdue, 2004 - present) and industrial statistician and researcher (at Bell Labs, 1972-2003), defined data science as an expanded technical area in the field of statistics. According to Cleveland’s proposal, the technical areas of data science consist of 6 components with corresponding suggested allocations apply to universities’ curriculum.
(25%) Multidisciplinary Investigations: data analysis collaborations in a collection of subject matter areas.
(20%) Models and Methods for Data: statistical models; methods of model building; methods of estimation and distribution based on probabilistic inference.
(15%) Computing with Data: hardware systems; software systems; computational algorithms.
(15%) Pedagogy: curriculum planning and approaches to teaching for elementary school, secondary school, college, graduate school, continuing education, and corporate training.
(5%) Tool Evaluation: surveys of tools in use in practice, surveys of perceived needs for new tools, and studies of the processes for developing new tools.
(20%) Theory: foundations of data science; general approaches to models and methods, computing with data, teaching, and tool evaluation; mathematical investigations of models and methods, computing with data, teaching, and evaluation.
Cleveland’s data science curriculum proposal has a balanced components of classical statistical and mathematical foundations for data science, computational and software tools and technologies, and domain knowledge. This article as republished in 2014 in Wiley’s journal Statistical Analysis and Data Mining together with his another article in which he listed the 6 key technical areas of data science are those that have an impact on how a data analyst analyses data in practice:
- Statistical theory;
- Statistical models;
- Statistical and machine learning methods;
- Algorithms for statistical and machine learning methods, and optimization;
- Computational environments for data analysis;
- Live analyses of data where results are judged by the findings, not the methodology and systems that where used.
By that time many universities and colleges including some key universities such as started offered undergraduate majors in data science and master’s program in data sciences. These college degree programs in data science are usually houses in mathematics and statistics, computer science and engineering, or business and information systems departments. Some of the key universities expand their statistics departments and rename it as Statistics and Data Science. All these movements in academia indicate that the Tukey’s prophesied new science has been growing to the field of data science.
1.2 The Coverage of the First Data Science Course
The technical foundation of data science is built partly on applied statistics and mathematics, computer science and information system, and domain knowledge. Many universities started DS programs at graduate level degrees or certificates from different traditional disciplines using the existing resources and faculty expertise. Because of these limitations, different programs deliver slightly different curricula with different emphases but teach commonalities to build DS foundation.
For the first DS course, different programs also deliver the content in different ways depending on faculty expertise. Most of the current data science foundation courses are methodological emphasis.
We designed this course as a project-based course. We teach the data science process not the isolated models or algorithms.
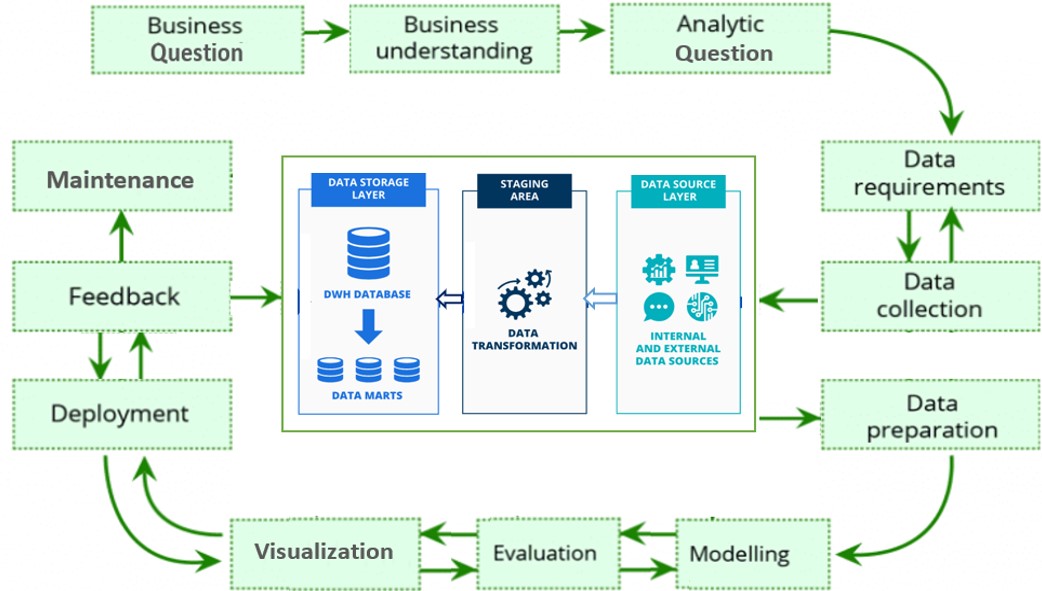
Figure 1.1: Data science process workflow
We will guide students to complete an end-to-end data science project that involves question formulation, data extraction and transformation, identification of models and algorithms, model deployment and monitoring, and effective communication. The final DS consulting project will be conducted in a workplace like environment and with real-world problems and using data sources. Through doing the project, students will
- understand the big picture of DS and its capacity of solving practical problems;
- sharpen their to skills in programming and information extraction and transforming;
- enhance their understanding and effective utilization of models and algorithms;
- improve their effective communications skills, particularly the information visualization;
- learn how to extract actionable information and effectively implement the DS product.
1.3 Tentative Topics
We will cover the following major topics in this course.
- Data science process
- Formulating analytic question from business questions
- Data source identification, collection, and processing
- EDA and Visualization in basic feature engineering
- Statistical models for data science
- Performance measures in predictive analytics
- Training, testing and cross validation - data-driven methods
- Survey of supervised machine learning algorithms and models
- Unsupervised algorithms
- Algorithm-based Feature engineering methods
- Model / algorithm deployment and updating (including real-time predictive analytics)
- Four-four workshop on a real-world data science consulting team project.