Topic 2 Data Science - A Big Picture
This note introduces the big picture of data science and tools and infrastructure needed for perform data science tasks. These include technical tools such as models and algorithms and data storage and extraction tools, etc.
2.1 Data Science Process
Although there are different versions of definition of data science, but the fundamental technical components have been well established for the field by the academic community. There is a consensus that the four pillars of data science are depicted in the following figure.
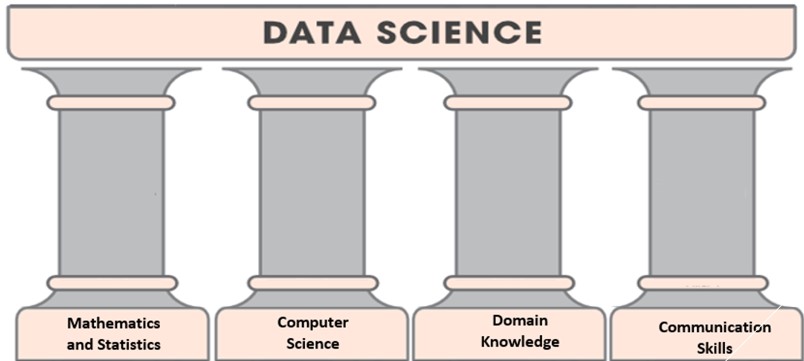
Figure 2.1: Four pillars of data science.
This is pretty much consistent with Tukey’s new science and Cleveland’s proposal of college DS curriculum.
2.1.1 What is Data?
According to the definition in Wikipedia,
Data is a set of values of qualitative or quantitative variables; restated, pieces of data are individual pieces of information. Data is measured, collected, and reported, and analyzed, whereupon it can be visualized using graphs or images. Data as a general concept refers to the fact that some existing information or knowledge is represented or coded in some form suitable for better usage or processing.
The data world of data science, data is all recordable information such as images, audios, and videos.
2.1.2 Data Storage and Retrieval
Once a business question is translated to an analytic questions, the next step is to identify data sources. This includes finding data sources in existing data warehouses in an organization or collecting data based on protocols or using external data sources. This stage involves data storage and retrieval. The following figure shows the simplest architecture of a data science professional will work with.
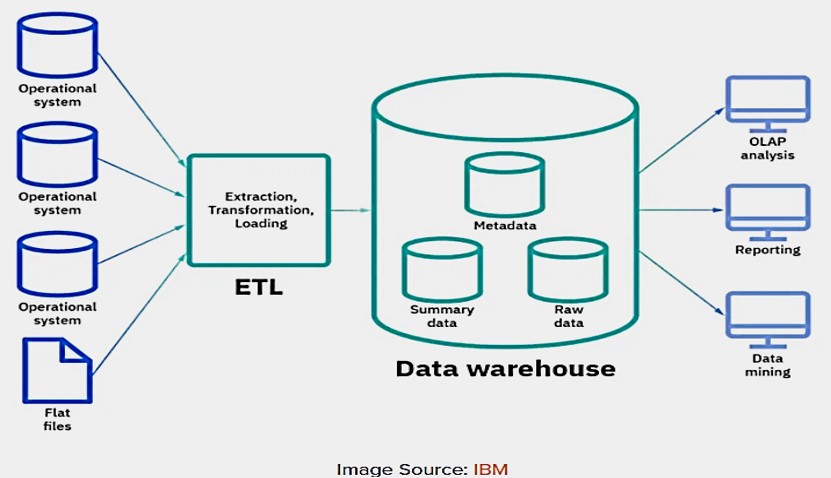
Figure 2.2: Basic architechute associated with data storage and retrieval.
2.1.3 Different DA Roles in Industry
There are different types of data science roles in industry. Depending on the specific job role and organizations, Different job titles were used for different job role.
Mathematical and Statistical analysis - statistician: This role uses Statistics Methods such as Descriptive statistics, EDA, regression analysis, time series and nonparametric analysis, etc. Sometimes, mathematical methods such mixture modeling and various optimization algorithms are also used when performing certain tasks.
Machine Learning Algorithms - Machine Learning Engineer: This role uses machine learning algorithms routinely in the work. Typical algorithms include classification algorithms (Rule-based, Tree-based methods, Kernel method-KNN, Naive Bayes, Support vector machine-SVM, Neural networks, etc.), Clustering Algorithms (K-mean, Hierarchical clustering) and Anomaly detection algorithms, etc.
Programming - Software Engineer: Database query languages (SQL and NoSQL), Script languages (such as Python, R, Julia, SAS, etc.), Data wrangling and cleaning using different software tools, creating visuals via coding, Basic software development skills (writing APIs), Writing industry standard production code.
Technology - IT and Data Engineer: This role uses database technology, big data technology, data science platforms, software programs, collaboration tools, communication tools.
Business Intelligence - Business analyst: This role requires a business mind set, project management skills and communication skills.
2.1.4 Cloud Computing
Cloud computing is the on-demand availability of application and infrastructure computing resources such as servers, storage, databases, networking, software, analytics, and intelligence — over the internet, without direct active management by the customer.
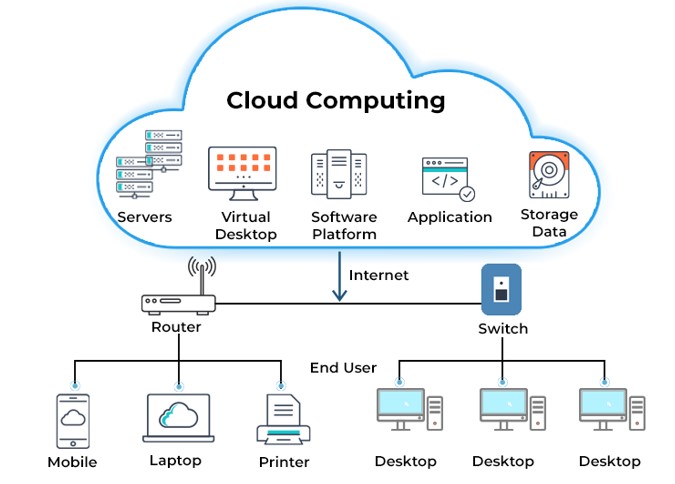
Figure 2.3: The architecture of cloud computing.
The key characteristics of cloud computing are
On-demand self-services: Users monitor and manage computing resources as necessary without the assistance of human administrators.
Broad network access: A wide range of hardware and established networks are usually used to deliver computing services.
Rapid elasticity: Resources for the computing services can be scaled up and down quickly as required.
Resource pooling: Ad hoc sharing of networks, servers, storage, apps, and services by several users and applications.
Resilient computing: computing services are ensured with high uptime and dependability.
Flexible pricing structures: including pay-per-use, subscription-based, and spot pricing.
Security: To safeguard the privacy of sensitive data and their users’ data.
Automation: Cloud computing services feature a high level of automation with little to no manual input.
2.2 From Business Questions to Analytic Question
Business questions (if any) are usually ambiguous. Quite often in practice, there is no business question but a description of business issues or goals. As an example, let’s assume a credit card company has been suffering fraud loss and decided to create a fraud detection team to reduce the current fraud loss.
2.2.1 Business Goal
Business Goal: The business goal of the executive team is to cut the current fraud loss by half within one year. The business goal is clear and achievable based on the current fraud loss in the credit card industry. The question is that the business goal does not operational information for the analytic and data science team.
In order to appropriately formulate the corresponding analytic question, we need to understand the business logic of this business goal - how credit card transactions are processed?
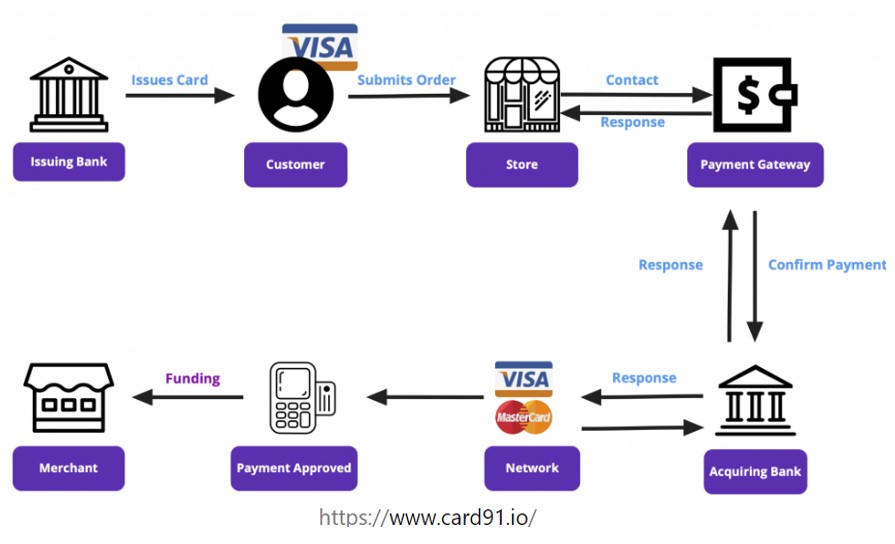
Figure 2.4: Credit card transaction processing workflow.
The electronic credit card payment process may be difficult to understand at first. The diagram above illustrates the workflow of payment process.
1. The cardholder swipes the card at the merchant POS in exchange for goods or services.
2. The merchant sends a request for payment authorization to their payment processor.
3. The payment processor submits transactions to the appropriate card association, eventually reaching the issuing bank.
4. Authorization requests are made to the issuing bank, including parameters such as CVV (card verification value), expiration date, etc. to validate the incoming transaction request.
5. The issuing bank approves or declines the request. The transaction can be declined in case of insufficient funds.
6. The issuing bank then sends the approval (or denial) statement back along the line to the card association, merchant bank, and finally to the merchant.
7. Merchants send batches of authorized transactions to their payment processor.
8. The payment processor passes transaction details to the card associations that communicate the appropriate debits with the issuing bank in their network.
9. The issuing bank charges the cardholder’s account for the amount of the transactions,
10. The issuing bank then transfers the appropriate amount for the transactions to the merchant bank, minus the interchange fees.
11. The merchant bank deposits funds into the merchant account.
If a fraudulent transaction was detected during the authorization process (the above steps 1- 6), there will be zero loss to the company. If the fraudulent transaction escaped from the authorization process, the company would lose at least one transaction, in general more if there is no way to identify them.
2.2.2 Analytic Question
Analytic Question: The high-level analytic question is how to identify fraudulent transactions and stop them? - This high-level analytic question is not operational since we cannot be based on this question to identify data. We still need to drill down to gather some granular information in order to develop actionable plans for data collection and analysis planning.
There are different types of fraud, different fraud has different patterns that require different pieces of information to identify.
- Identity theft fraud?
- Lost card fraud?
- Application fraud?
- Account takeover fraud?
Fraud interception at authorization process - proactive action for zero loss.
If the initial fraudulent transaction escaped from the fraud check during the authorization process, fraudsters would continue stealing, what analytic action we should take.
Based on the above sub-analytic questions, we make analytic plans and create a set of sub-tasks to identify data sources and models and algorithms to build a detection system. This means, we will not work with one model or algorithm, we need a set of potentially very different models and algorithms to tackle the seemingly simple business question.
Types of Models/Algorithms and Required Data Sources: We will use two of the above sub-analysis questions to illustrate the potential models/algorithms and relevant information needed to build identification systems.
Proactive Fraud Detection: This detection is most favorable is it intercepts the fraud before the transaction is complete (i.e., the transaction will be declined). Some of the information such as geolocation of the merchant site, time and previous transaction site and time, card verification value (CVV), expiration, credit limit, etc. in the initial fraud check. This types of information can be used to develop business rules (expert system). Of cause, we can also build predictive models using this information.
Application Fraud: A fraudster can use fake information to apply for credit and then use the credit and discard the card. The first transaction is not easy to catch, what analytic models and algorithms can do is to detect the card and suspend it as soon as possible. The more effective way to stop application fraud is to build models to prevent potential application fraud during card application. The information needed to build the model can be extracted from the application and personal credit information and other relevant information from third-party.
Identity Theft Fraud: Identity fraud is common where criminals make purchases or obtain cash advances in the victim’s name. This can be with an existing account, via theft of victim’s physical credit card or victim’s account numbers and PINs, or by opening new credit card accounts in victim’s name. Because the fraudsters information is not available, we can use customers’ proxy information on spending patterns to build models.
The types of algorithms and models for fraud identification will be discussed in more detail in the subsequent chapters.
2.3 Concepts of Relational Databases and SQL
Every data science professional should have basic knowledge of databases and data warehouse to accomplish all data science and other analytic projects.
2.3.1 What is Database?
A database is a collection of related data set collected from the real world. It is designed to be built and populated with data for a specific task. It is also a building block of data solutions. A database
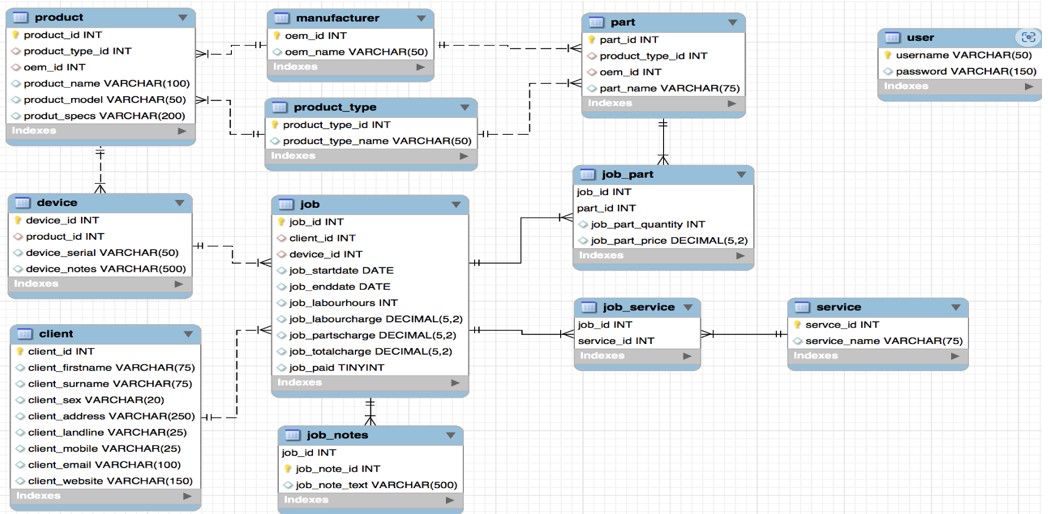
Figure 2.5: Relational datatables in a relational database.
- offers the security of data and its access;
- offers a variety of techniques to store and retrieve data;
- acts as an efficient handler to balance the requirement of multiple applications using the same data;
- A DBMS offers integrity constraints to get a high level of protection to prevent access to prohibited data;
- allows users to access concurrent data in such a way that only a single user can access the same data at a time.
2.3.2 What is a Data Warehouse?
A data warehouse is an information system which stores historical and commutative data from single or multiple sources. It is designed to analyze, report, and integrate transaction data from different sources.
A basic structure of an organization’s data warehouse is depicted in the following.
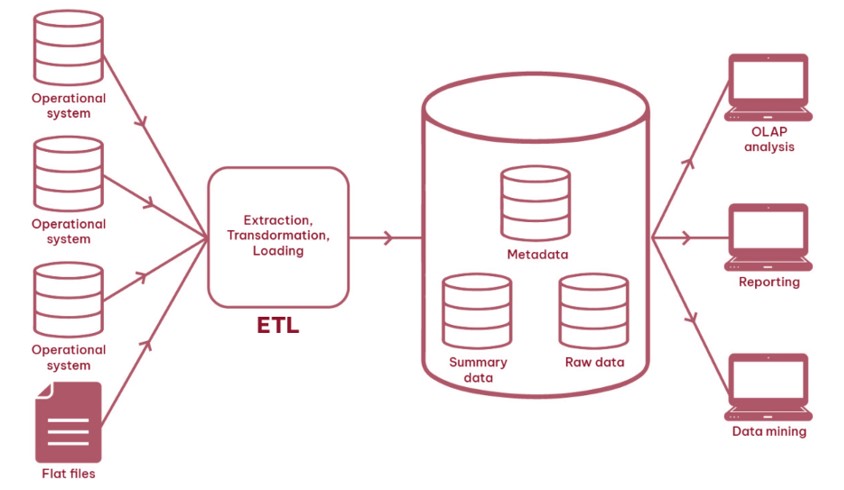
Figure 2.6: Basic structure of data warehouse.
A data warehouse.
- helps business users to access critical data from some sources all in one place;
- provides consistent information on various cross-functional activities;
- helps you to integrate many sources of data to reduce stress on the production system.
- helps you to reduce TAT (total turnaround time) for analysis and reporting.
- helps users to access critical data from different sources in a single place so, it saves user’s time of retrieving data information from multiple sources. You can also access data from the cloud easily.
- allows you to store a large amount of historical data to analyze different periods and trends to make future predictions.
- enhances the value of operational business applications and customer relationship management systems
- separates analytics processing from transactional databases, improving the performance of both systems
- provides more accurate reports.
2.3.3 Difference between Database and Data Warehouse
Both databases and data warehouses use relational data structures. But they are different. A data warehouse exists as a layer on top of another database or databases (usually OLTP databases). The following table lists the difference between two systems.
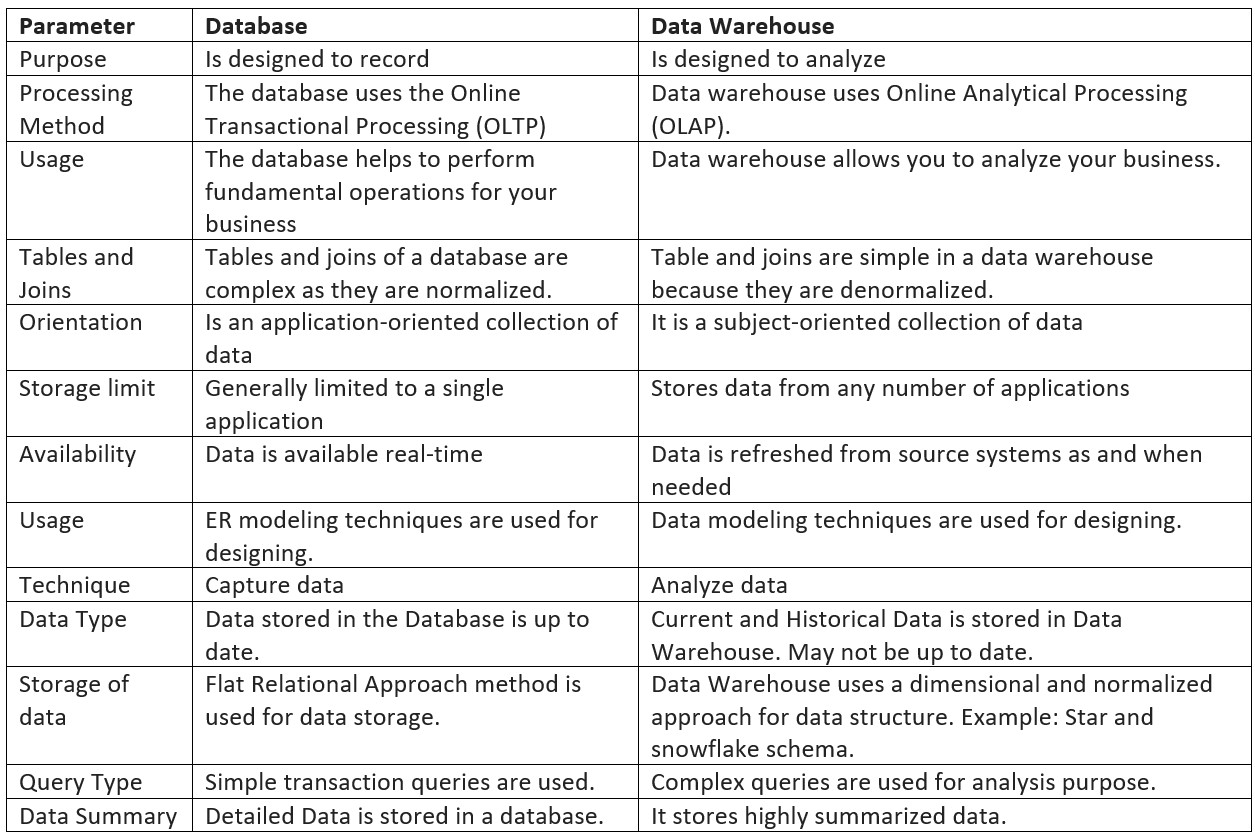
Figure 2.7: Comparison between database and data warehouse.
2.3.4 Database Management System (DBMS)
Database Management Systems (DBMS) are software systems used to store, retrieve, and run queries on data. DBMS manages the data, the database engine, and the database schema, allowing for data to be manipulated or extracted by users and other programs. This helps provide data security, data integrity, concurrency, and uniform data administration procedures.
The following figure depicts the structure of a simple DBMS.
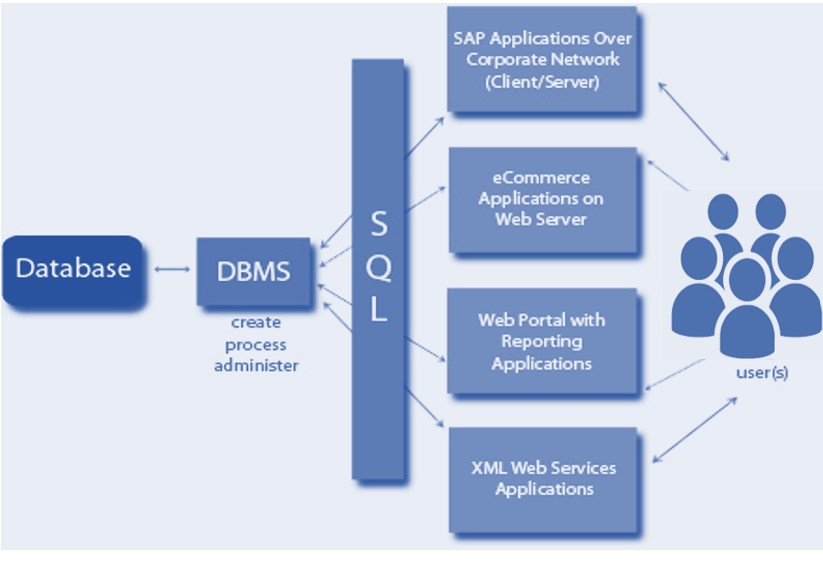
Figure 2.8: Comparison between database and data warehouse.
Structured query language (SQL) is a programming language for storing and processing information in a relational database. A relational database stores information in tabular form, with rows and columns representing different data attributes and the various relationships between the data values. We can use SQL statements to store, update, remove, search, and retrieve information from the database. We can also use SQL to maintain and optimize database performance.
2.3.5 Some Definitions and Notations of Relational Tables
- Names Associated with Relational Tables
Name – each relation in a relational database should have a name that is unique among other relations.
Attribute – each column in a relation.
The degree of the relation – the total number of attributes for a relation.
Tuple – each row in a relation.
The cardinality of the relation – the total number of rows in a relation.
- Operations among Relational Tables
In a relational database, we can define several operations to create new relations out of the existing ones.
Basic operations are
- Unary Operation: Insert, Delete, Update, Select, Project,
- Binary Operation: Join, Union, Intersection, Difference.