Topic 11 Classification Performance Metrics
Since the performance measures for regression models are relatively simple, we focus on the commonly used performance measures of binary classification models and algorithms.
11.1 Confusion Matrix for Binary Decision
We have used the logistic regression model as an example to illustrate the cross-validation method. Most of the performance measures are defined based on the confusion matrix.
Consider a binary classification (prediction) model that passed all diagnostics and model selection processes. Any binary decision based on the model will inevitably result in two possible errors that are summarized in the following confusion matrix (as mentioned and used in the previous case study).
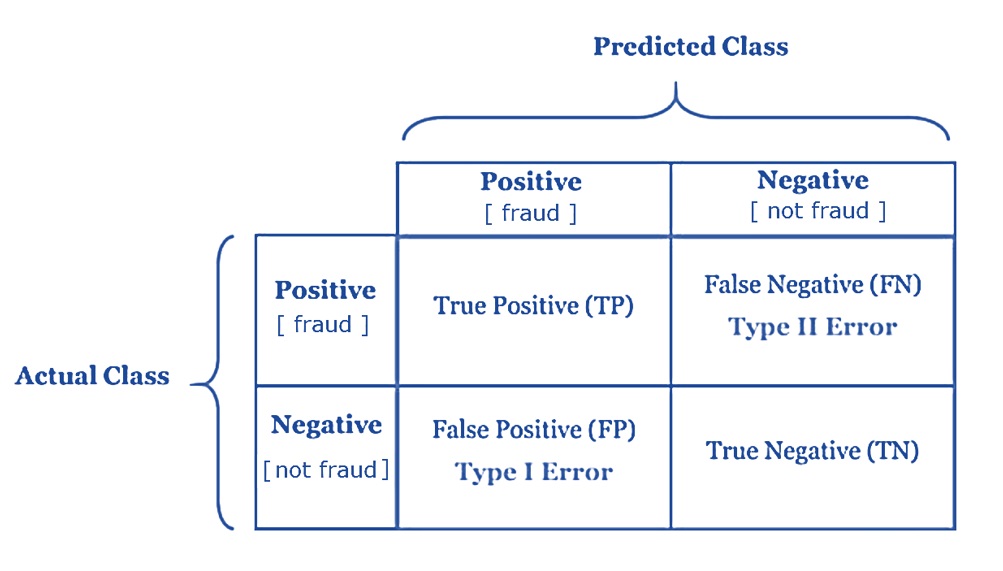
Figure 11.1: The layout of the binary decision confusion matrix.
The following are a few probabilities that will be used as the element in the definition of performance measures.
True Positive (TP) is the number of correct predictions that an example is positive which means positive class correctly identified as positive - P[Predicted Positive | Actual Positive].
False Negative (FN) is the number of incorrect predictions that an example is negative which means positive class incorrectly identified as negative - P[Predicted Negative | Actual Positive].
False positive (FP) is the number of incorrect predictions that an example is positive which means negative class incorrectly identified as positive - P[Predicted Positive | Actual Negative].
True Negative (TN) is the number of correct predictions that an example is negative which means negative class correctly identified as negative - P[Predicted Negative | Actual Negative].
The above conditional probabilities are defined by conditioning on the actual status. These probabilities are used to assess the model performance in the stage of model development.
One of the important steps in the data science process is to monitor the performance of the deployed models in the production environment. We can use a different set of conditional probabilities for this purpose.
Positive Predictive Value (PPV) is the percentage of predictive positives that are confirmed to be positive - P[ Confirmed Positive | Predicted Positive]. In the clinical term, PPV is the percentage of patients with a positive test who actually have the disease.
Negative Predictive Value (NPV) is the percentage of predictive positives that are confirmed to be positive - P[ Confirmed Negative | Predicted Negative]. In the clinical term, NPV is the percentage of patients with a negative test who do not have the disease.
11.2 Local Performance Measures (for Model Development)
For ease of understanding, we use the following hypothetical confusion matrix based on the clinical binary decision.

Figure 11.2: The layout of the clinical binary decision confusion matrix.
The following performance measures are defined based on the above confusion matrix.
- Classification Accuracy measures the percentage of labels that are correctly predicted.
\[ \mbox{accuracy} = \frac{a + d}{a + b + c + d} \]
- Precision is a valid performance measure for a class whose distribution is imbalanced (one class is more frequent than others). In this case, even if we predict all samples as the most frequent class, we would get a high accuracy rate. This does not make sense at all because your model is not learning anything, and is just predicting everything as the top class. Precision measures the percentage of true positives among all predictive positives.
\[ \mbox{precision} = \frac{a}{a + b} \]
- Recall is another important metric, which is defined as the fraction of samples from a class that is correctly predicted by the model. More formally,
\[ \mbox{Recall} = P[\mbox{predict disaese} | \mbox{Actual disease}] = \frac{a}{a+c} \]
- F1 Score: Depending on the application, we may want to give higher priority to recall or precision. But there are many applications in which both recall and precision are important. Therefore, it is natural to think of a way to combine these two into a single metric. One popular metric which combines precision and recall is called F1-score, which is the harmonic mean of precision and recall defined as
\[ F_1 = \frac{2 \times \mbox{precision}\times \mbox{recall}}{\mbox{precision}+\mbox{recall}} \]
The generalized version of the F-score is defined below. As we can see F1-score is a special case of \(F_{\beta}\) when \(\beta= 1\).
\[ F_1 = \frac{(1+\beta^2) \times \mbox{precision}\times \mbox{recall}}{\beta^2(\mbox{precision}+\mbox{recall})} \]
It is good to mention that there is always a trade-off between the precision and recall of a model. If we want to make the precision too high, we would end up seeing a drop in the recall rate, and vice versa.
11.3 Global Performance Measures
Sensitivity and specificity are two other popular metrics mostly used in medical and biology-related fields. They are used as building blocks for well-known global measures such as ROC and the area under the curve (AUC). They are defined in the forms of conditional probability in the following based on the above clinical confusion matrix.
- Sensitivity (True Positive Rate, Recall) - The probability of those who received a positive result on this test out of those who actually have a disease (when judged by the ‘Gold Standard’). It is the same as recall.
\[ \mbox{sensitivity} = \frac{a}{a+c} \]
- Specificity (True Negative Rate) - The probability of those who received a negative result on this test out of those who do not actually have the disease (when judged by the ‘Gold Standard’).
\[ \mbox{specificity} = \frac{d}{b + d} \]
Next, we define a metric to assess the global performance measure for the binary decision models and algorithms. From the previous case study of cross-validation. Each candidate cut-off probability defines a confusion matrix and, consequently, sensitivity and specificity associated with the confusion matrix.
- An ROC curve (receiver operating characteristic curve) is a graph showing the performance of a classification model at all classification thresholds. This curve plots two parameters: sensitivity and (1 - specificity). Note that the (1 - specificity = false positive rate).
In other words, the ROC curve is the plot of the False Positive Rate (FPR) against the True Positive Rate (TPR) calculated from each decision boundary (such as the cut-off probability in logistic models).
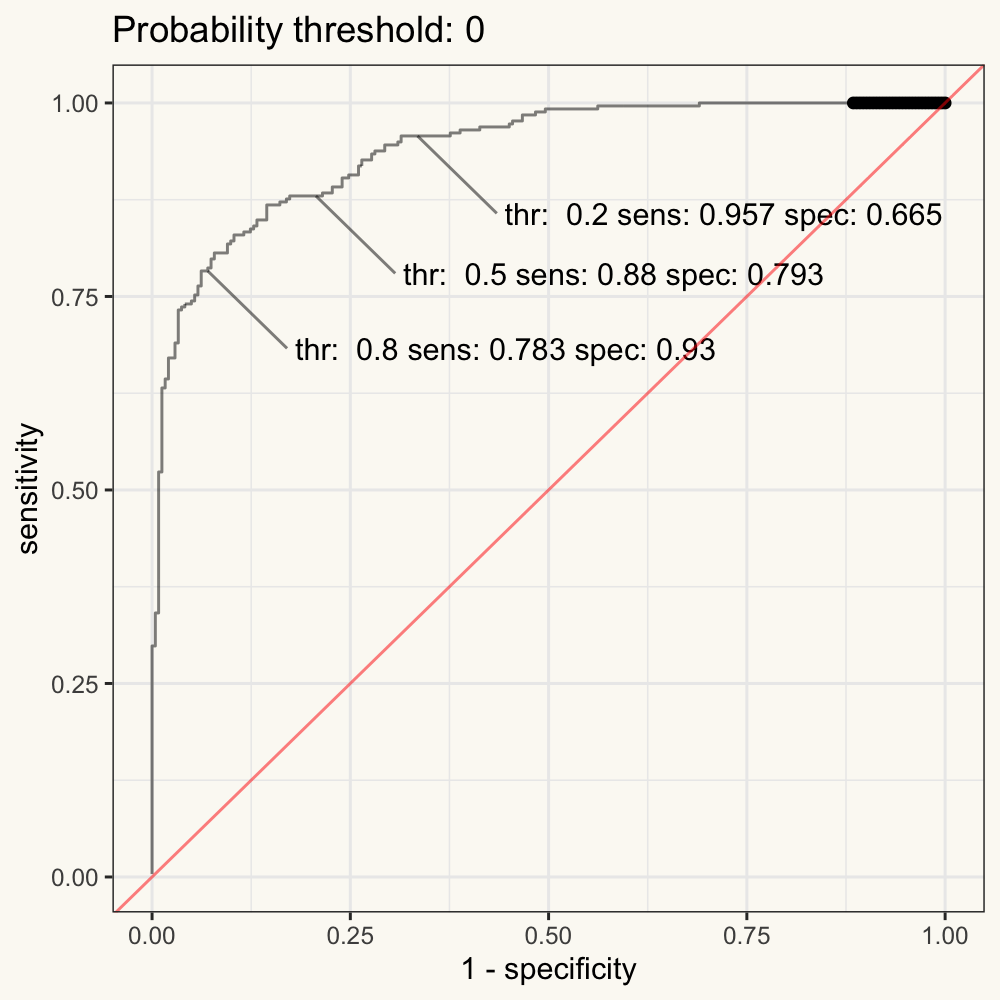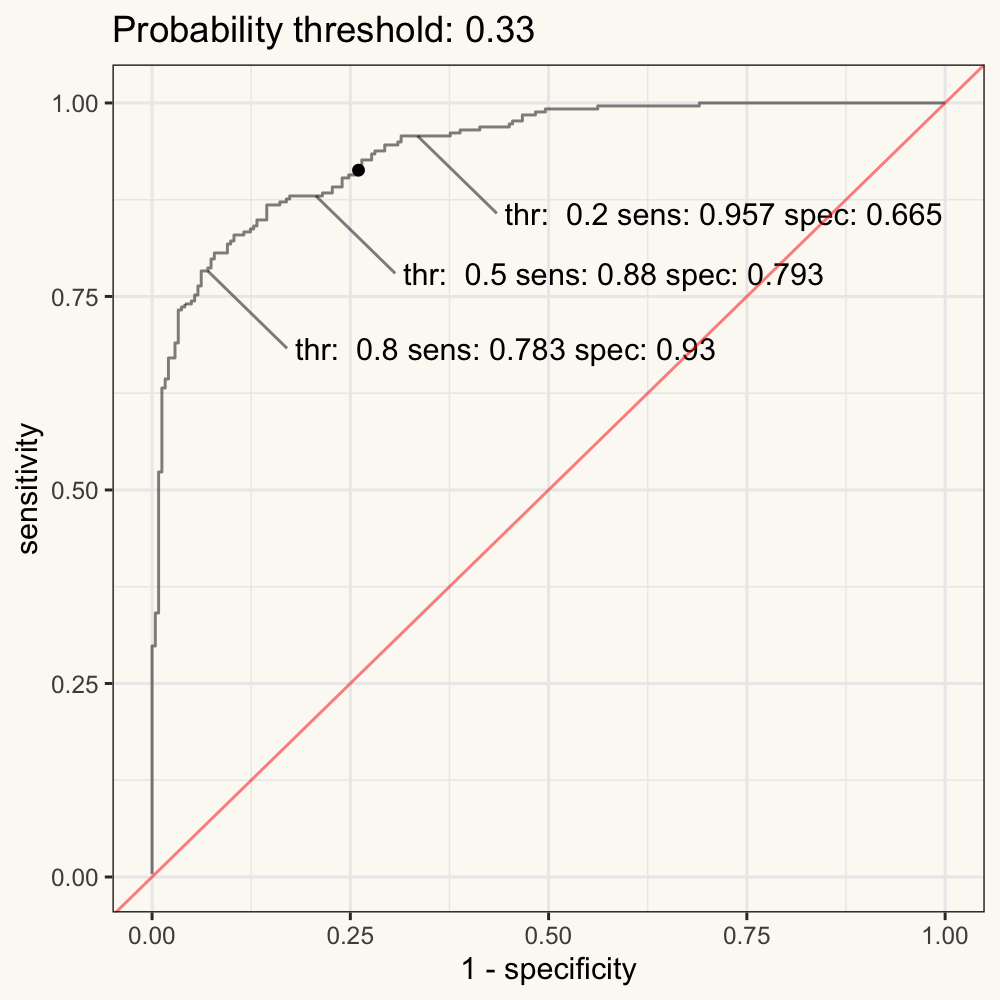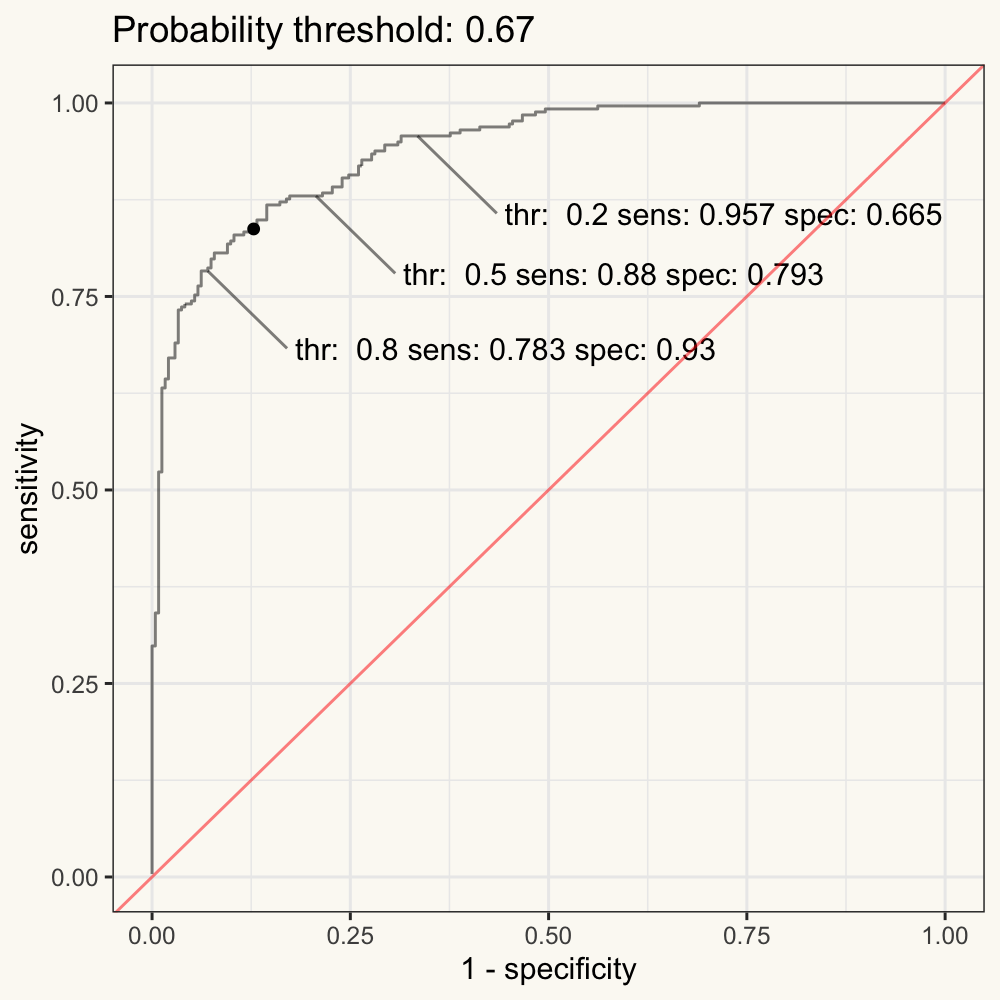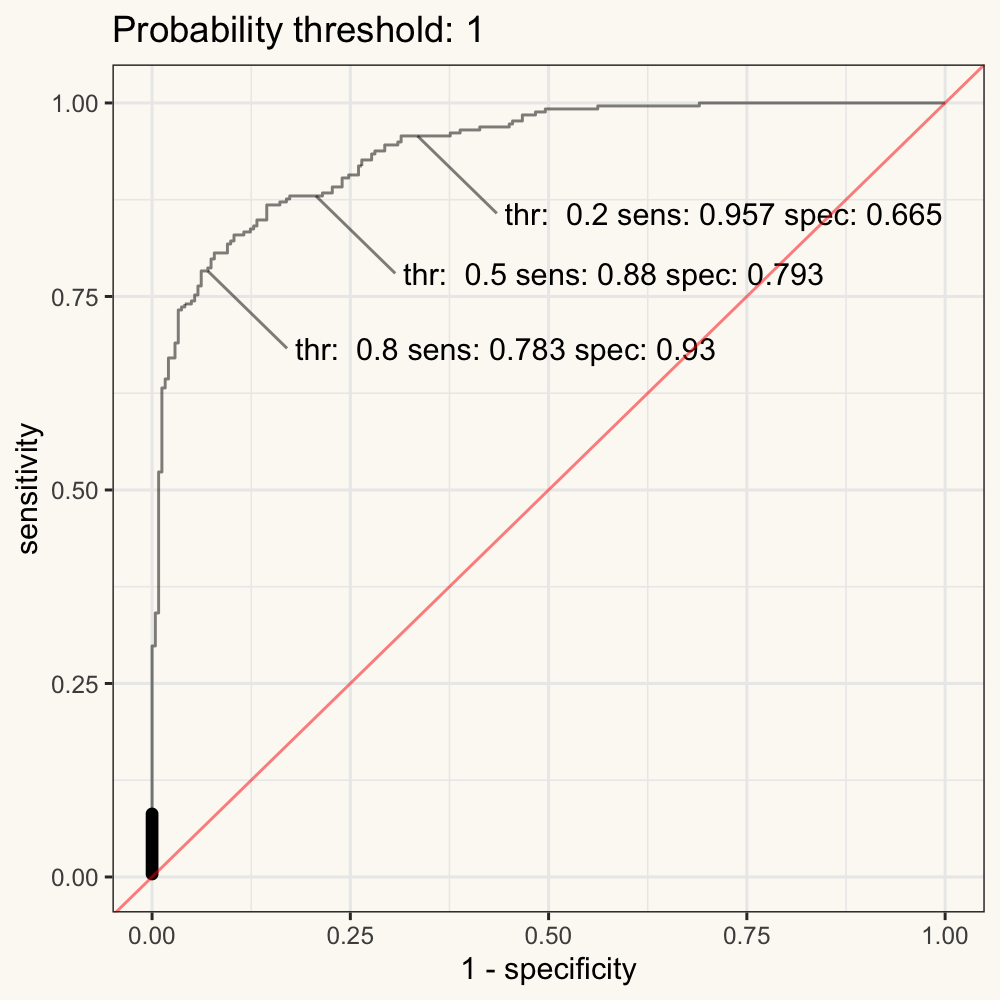
Figure 11.3: Figure 3. Animated ROC curve.
The primary use of the ROC is to compare the global performance between candidate models (that are not necessarily to be within the same family). As an illustrative example, the following ROC curves are calculated based on a logistic regression model and a support vector machine (SVM). Both are binary classifiers.
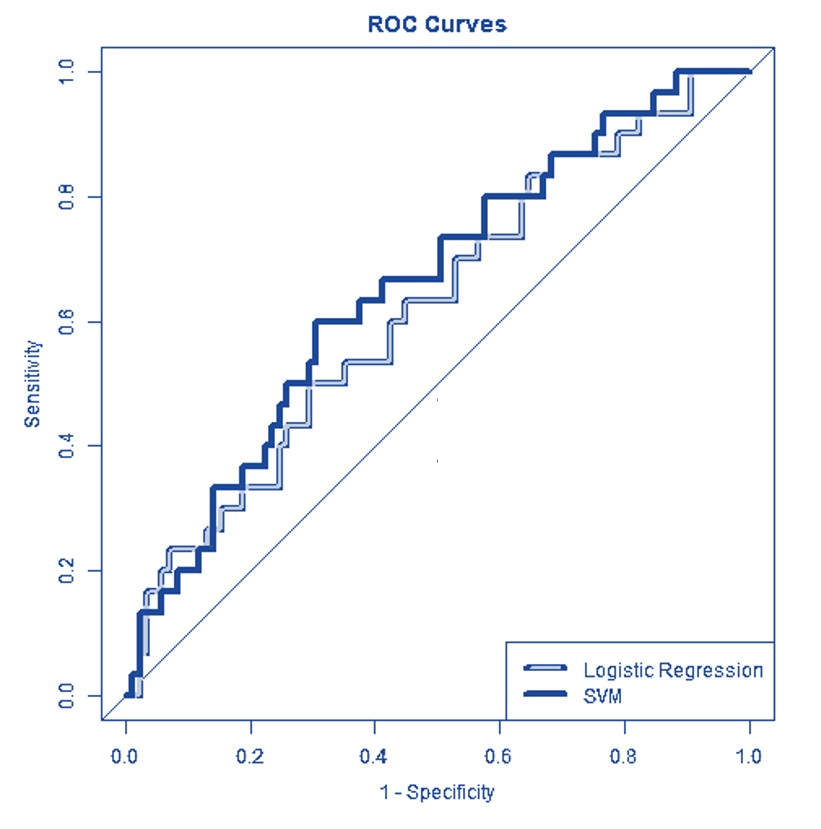
Figure 11.4: Figure 4. Using ROC for model selection.
We can see that the SVM is globally better than the logistic regression. However, at some special decision boundaries, the logistic regression model is locally better than SVM.
- Area Under The Curve (AUC)
If two ROC curves intersect at least one point, we may want to report the area under the curves (AUC) to compare the global performance between the two corresponding models. See the illustrative example below.
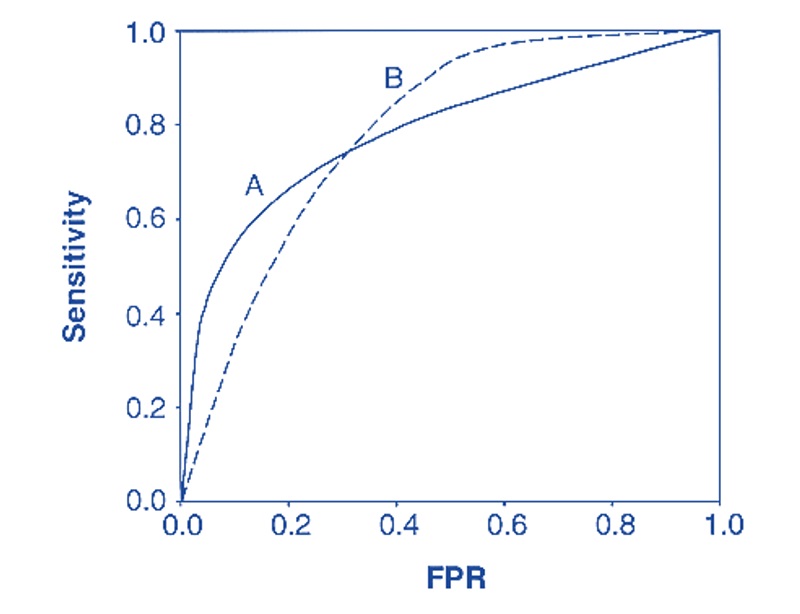
Figure 11.5: Using ROC for model selection.